Adaptive ML
What is Adaptive ML?
Time series models that are updated often outperform their static counterparts. You can almost always improve your model's performance with an simple update, by continuously training them as data comes in.
What is Adaptive Backtesting?
With Adaptive Backtesting, you take an existing time series, and train multiple models, as you simulate your model's performance over time:

This way, you can turn almost all of your data into an out of sample test set.
Instead of only looking at the last 1 year, 1 month of out-of-sample predictions, you can simulate "live deployment" over almost the whole time series.
How is it different to Time Series Cross-Validation?
Inside a test window, and during deployment, fold provides a way for a model to access the last value.

This way, fold blends:
-
the speed of (Mini-)batch Machine Learning.
-
with the accuracy of Adaptive (or Online) Machine learning.
What's wrong with classical Backtesting ("Time Series Cross-Validation")?
A simple example with the Naive model (that just repeats the last value):
Classical Backtesting
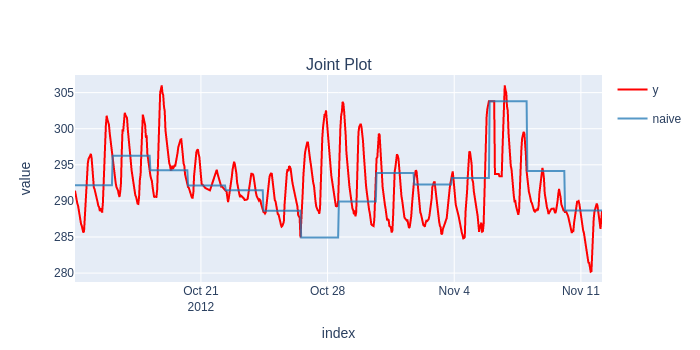
The model is static, and repeats the last value for the whole test window.
Adaptive Backtesting
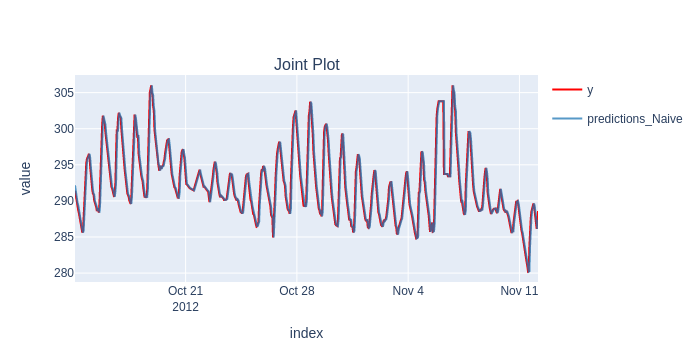
The model is up-to-date, and repeats the last value, as you'd expect.
How is that implemented?
There are two ways to have a model that's up-to-date:
-
The model parameters are updated on each timestamp, within the test window. This can be really slow, but a widely available option. See the Speed Comparison section.
-
Give the model special access to the last value, while keeping its parameters constant. This is what
folddoes with all of our models. This means that the model is still only trained once per fold, providing an order of magnitude speedup, compared to the first method.
More
The different strategies are implemented with Splitters in fold.